华为云环境搭建
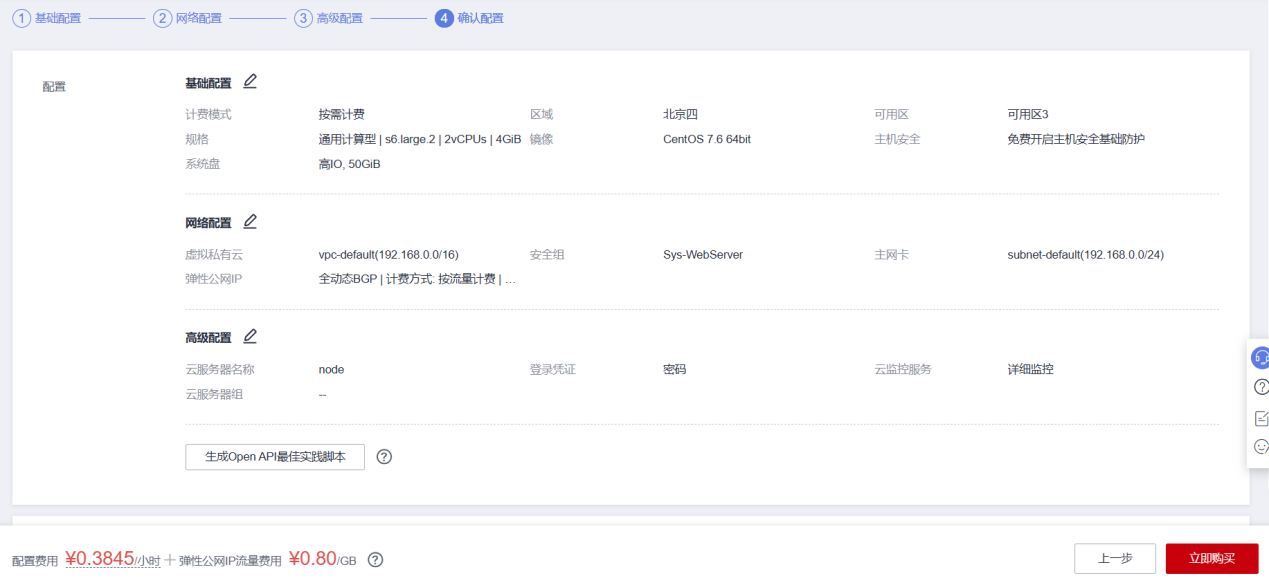
华为云ECS
ECS购买需遵循以下规格:
- 计费模式:按需计费
- 可用区:可用区一
- CPU架构:x86
- 规格: 2vcpus|8GB
- 系统:CentOS7.6
- 系统盘:超高IO、100GB。
- 网络:按流量计费
- 其他配置:默认
完成基础配置,网络配置,高级配置。购买4台ECS
对象存储服务OBS
区域选择与ECS相同。其他配置默认
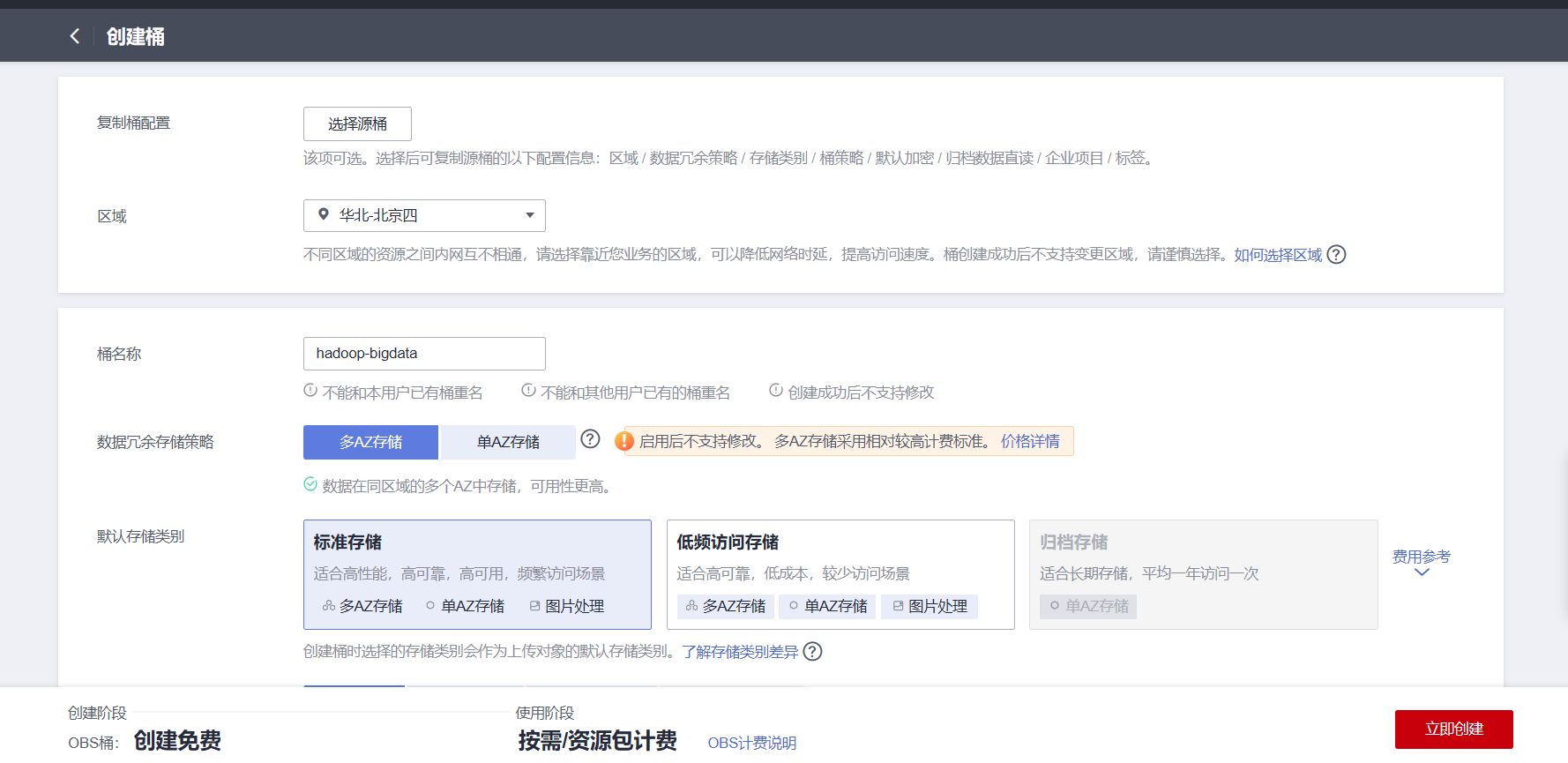
创建并行文件系统
配置默认
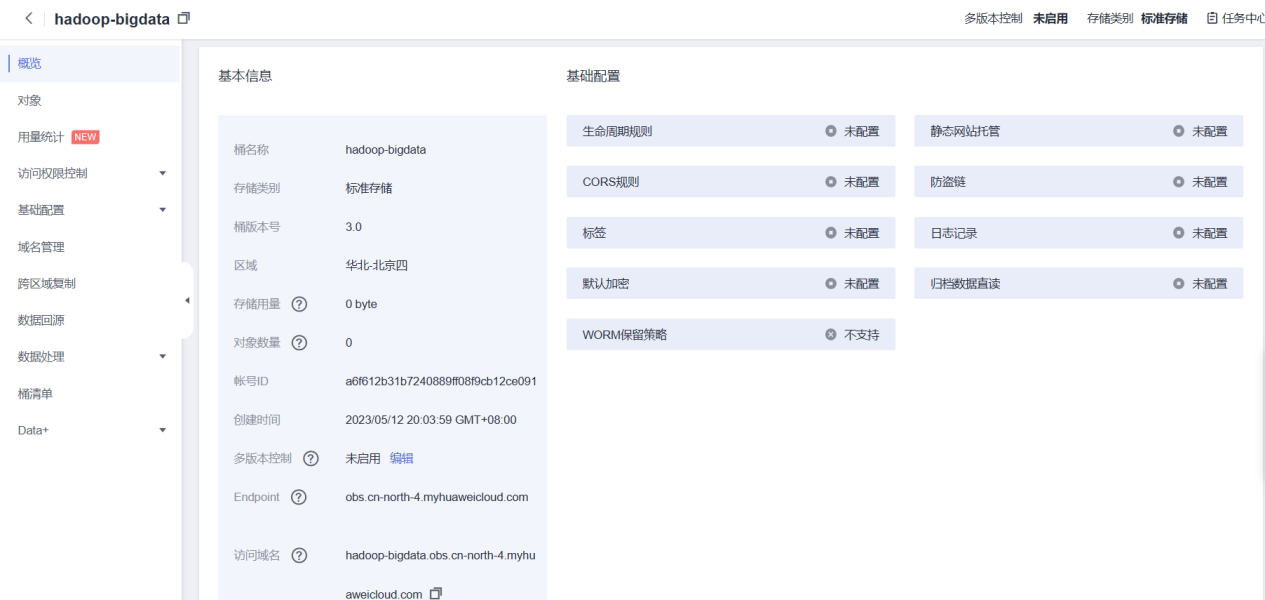
进入创建的OBS桶,记录参数endpoint
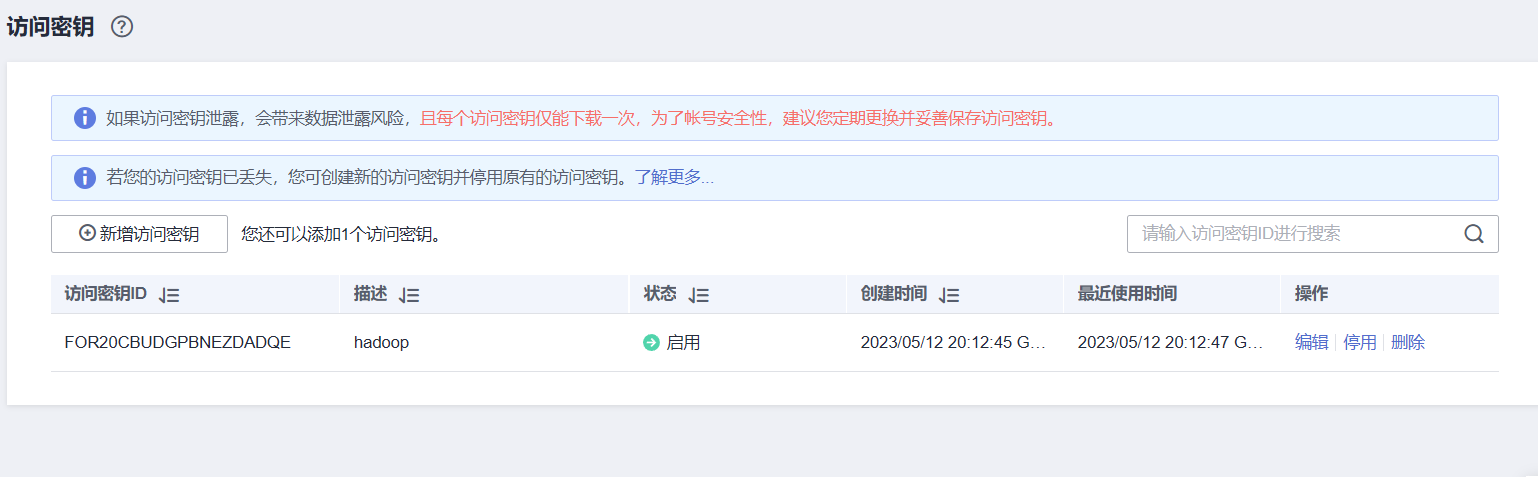
获取AK/SK
华为云页面右上角“用户名”,下拉选择“我的凭证”,点击“访问秘钥”。新增访问秘钥,根据提示进行操作,得到文件“credentials.csv”,打开即可得到AK/SK

Hadoop集群搭建
通过搭建开源Hadoop集群,掌握Hadoop搭建方法。并且使开源Hadoop与华为云OBS服务互联,使Hadoop集群可读取OBS数据。
配置ECS
登录三个节点服务器
下载hadoop安装包
cd /root
wget https://bigdata-tools-hw.obs.cn-north-1.myhuaweicloud.com/hadoop-2.8.3.tar.gz下载OBSFileSystem相关jar包
cd /root
wget https://bigdata-tools-hw.obs.cn-north-1.myhuaweicloud.com/hadoop-huaweicloud-2.8.3-hw-39.jar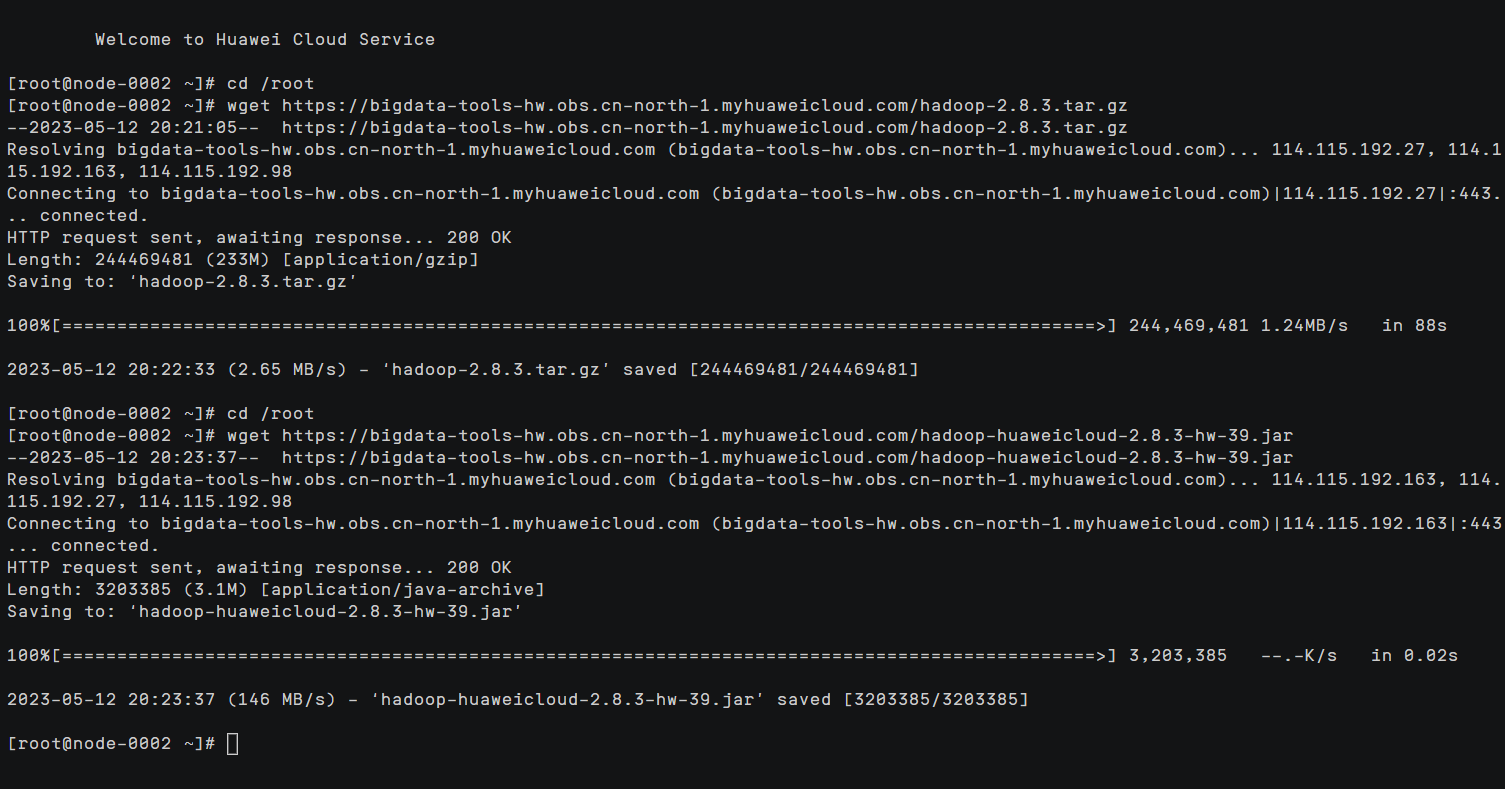
安装JDK
下载并拷贝jdk8至/usr/local/java,并解压缩
cd /usr/local/
mkdir java
tar -zxvf jdk-8u351-linux-x64.tar.gz设置环境变量
vim /etc/profile按“i”进入编辑模式,使用hjkl键或方向键移动光标,在文件最后添加以下代码:
JAVA_HOME=/usr/local/java/jdk1.8******
export PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME按“Esc”退出编辑模式,输入“:wq”并按回车,保存退出。
执行以下命令,使新增配置生效。
source /etc/profile执行以下命令,验证jdk安装并配置成功。
java –version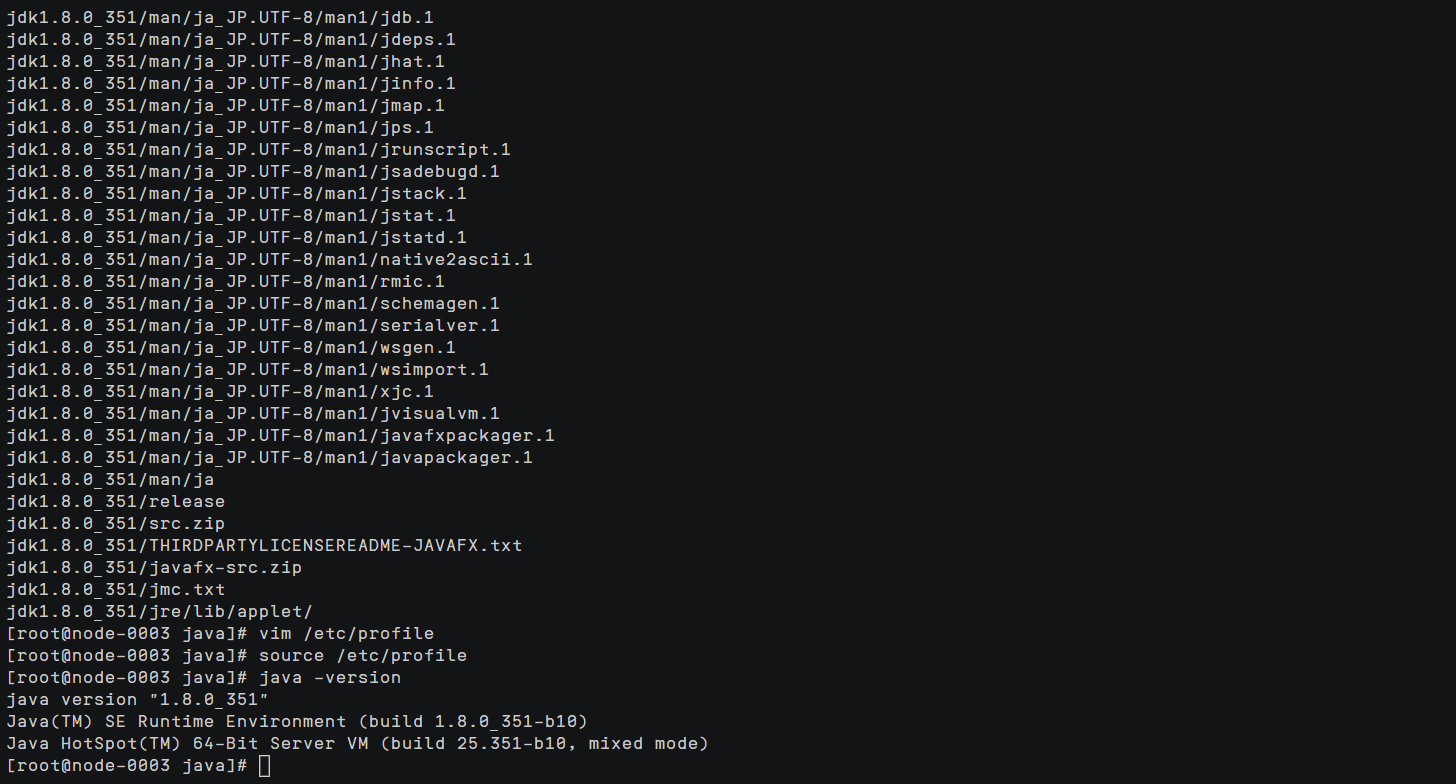
配置hosts文件
vim /etc/hosts添加
192.168.0.46 node-0001
192.168.0.123 node-0002
192.168.0.148 node-0003配置节点互信
各节点执行以下命令
ssh-keygen -t rsa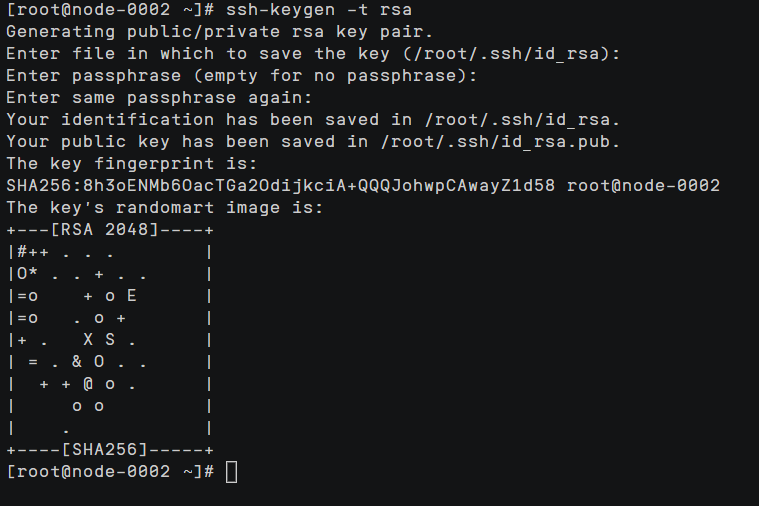
各节点执行:
cat /root/.ssh/id_rsa.pub
复制该命令在各节点的输出内容。
各节点执行:
vim /root/.ssh/authorized_keys输入各节点的复制内容,保存退出。
各节点执行:ssh node-0001~node-0003,选择yes后,确保能够无密码跳转到目标节点
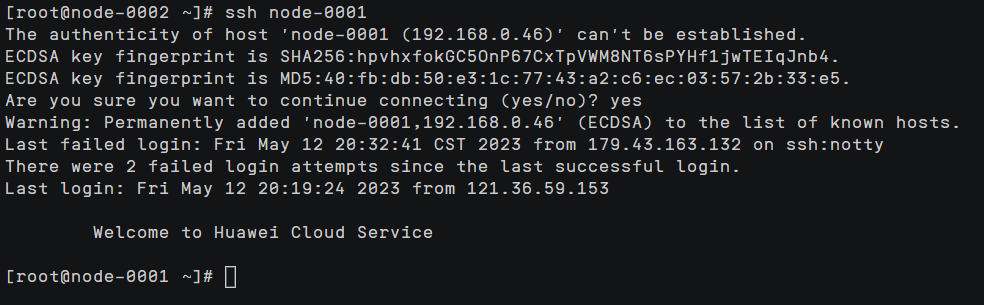
搭建Hadoop集群
创建目录
各节点执行:
mkdir -p /home/modules/data/buf
mkdir -p /home/nm/localdir登录node-0001节点,解压hadoop安装包
cd /root
cp hadoop-2.8.3.tar.gz /home/modules/
cd /home/modules/
tar -zxvf hadoop-2.8.3.tar.gz配置hadoop core-site.xml配置文件
node-0001节点执行下列命令:
vim /home/modules/hadoop-2.8.3/etc/hadoop/core-site.xml参数配置:
<configuration>
<property>
<name>fs.obs.readahead.inputstream.enabled</name>
<value>true</value>
</property>
<property>
<name>fs.obs.buffer.max.range</name>
<value>6291456</value>
</property>
<property>
<name>fs.obs.buffer.part.size</name>
<value>2097152</value>
</property>
<property>
<name>fs.obs.threads.read.core</name>
<value>500</value>
</property>
<property>
<name>fs.obs.threads.read.max</name>
<value>1000</value>
</property>
<property>
<name>fs.obs.write.buffer.size</name>
<value>8192</value>
</property>
<property>
<name>fs.obs.read.buffer.size</name>
<value>8192</value>
</property>
<property>
<name>fs.obs.connection.maximum</name>
<value>1000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-0001:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/modules/hadoop-2.8.3/tmp</value>
</property>
<property>
<name>fs.obs.access.key</name>
<value>FOR20CBUDGPBNEZDADQE</value>
</property>
<property>
<name>fs.obs.secret.key</name>
<value>5TZnFhulDt04EG1lfMzgdYCi8OMg6HwasWEcGBkO</value>
</property>
<property>
<name>fs.obs.endpoint</name>
<value>obs.cn-north-4.myhuaweicloud.com:5080</value>
</property>
<property>
<name>fs.obs.buffer.dir</name>
<value>/home/modules/data/buf</value>
</property>
<property>
<name>fs.obs.impl</name>
<value>org.apache.hadoop.fs.obs.OBSFileSystem</value>
</property>
<property>
<name>fs.obs.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.obs.fast.upload</name>
<value>true</value>
</property>
<property>
<name>fs.obs.socket.send.buffer</name>
<value>65536</value>
</property>
<property>
<name>fs.obs.socket.recv.buffer</name>
<value>65536</value>
</property>
<property>
<name>fs.obs.max.total.tasks</name>
<value>20</value>
</property>
<property>
<name>fs.obs.threads.max</name>
<value>20</value>
</property>
</configuration>注:fs.obs.access.key、fs.obs.secret.key、fs.obs.endpoint、fs.defaultFS需根据实际情况修改
配置hdfs-site.xml
node-0001节点执行下列命令:
vim /home/modules/hadoop-2.8.3/etc/hadoop/hdfs-site.xml参数配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-0001:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node-0001:50091</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/modules/hadoop-2.8.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/modules/hadoop-2.8.3/data/datanode</value>
</property>
</configuration>注:主机名node-0001需要根据实际替换。
配置yarn-site.xml
node-0001节点执行下列命令:
vim /home/modules/hadoop-2.8.3/etc/hadoop/yarn-site.xml参数配置如下:
<configuration>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/nm/localdir</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>28672</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>3072</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>28672</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>38</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>38</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-0001</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node-0001:19888/jobhistory/logs</value>
</property>
</configuration>注:主机名node-0001需要根据实际情况修改。
配置mapred-site.xml
node-0001节点执行下列命令:
cd /home/modules/hadoop-2.8.3/etc/hadoop/
mv mapred-site.xml.template mapred-site.xml
vim /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml参数配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node-0001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node-0001:19888</value>
</property>
<property>
<name>mapred.task.timeout</name>
<value>1800000</value>
</property>
</configuration>注:主机名node-0001需要根据实际情况修改。
配置slaves
node-0001节点执行下列命令:
vim /home/modules/hadoop-2.8.3/etc/hadoop/slaves删除原有内容,添加内容如下:
node-0002
node-0003配置hadoop环境变量
node-0001节点执行下列命令:
vim /home/modules/hadoop-2.8.3/etc/hadoop/hadoop-env.sh添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_351配置jar包
node-0001节点执行下列命令:
cd /root
cp hadoop-huaweicloud-2.8.3-hw-39.jar /home/modules/hadoop-2.8.3/share/hadoop/common/lib/
cp hadoop-huaweicloud-2.8.3-hw-39.jar /home/modules/hadoop-2.8.3/share/hadoop/tools/lib
cp hadoop-huaweicloud-2.8.3-hw-39.jar /home/modules/hadoop-2.8.3/share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib/
cp hadoop-huaweicloud-2.8.3-hw-39.jar /home/modules/hadoop-2.8.3/share/hadoop/hdfs/lib/分发hadoop包到各节点
node-0001下执行下列命令:
# 分发hadoop包到node2
scp -r /home/modules/hadoop-2.8.3/ root@node-0002:/home/modules/
# 分发hadoop包到node3
scp -r /home/modules/hadoop-2.8.3/ root@node-0003:/home/modules/配置环境变量
各节点执行:
vim /etc/profile在文件尾部添加如下内容:
export HADOOP_HOME=/home/modules/hadoop-2.8.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CLASSPATH=/home/modules/hadoop-2.8.3/share/hadoop/tools/lib/*:$HADOOP_CLASSPATHsource /etc/profilenamenode初始化
node-0001节点执行namenode初始化
执行下列命令:
hdfs namenode -format初始化成功后,启动hdfs。
node-0001节点执行
start-all.sh执行hdfs命令
hdfs dfs -mkdir /bigdata查看集群部署报告
hdfs dfsadmin -report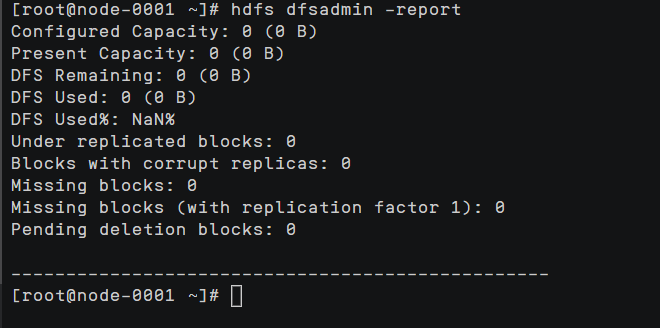
主要原因是 每台机器的/etc/hosts 错误
127.0.0.1 localhost
127.0.1.1 node-000*
192.168.x.x node-0001
192.168.x.x node-0002
192.168.x.x node-0003把127.0.1.1 node-000*这一行删掉
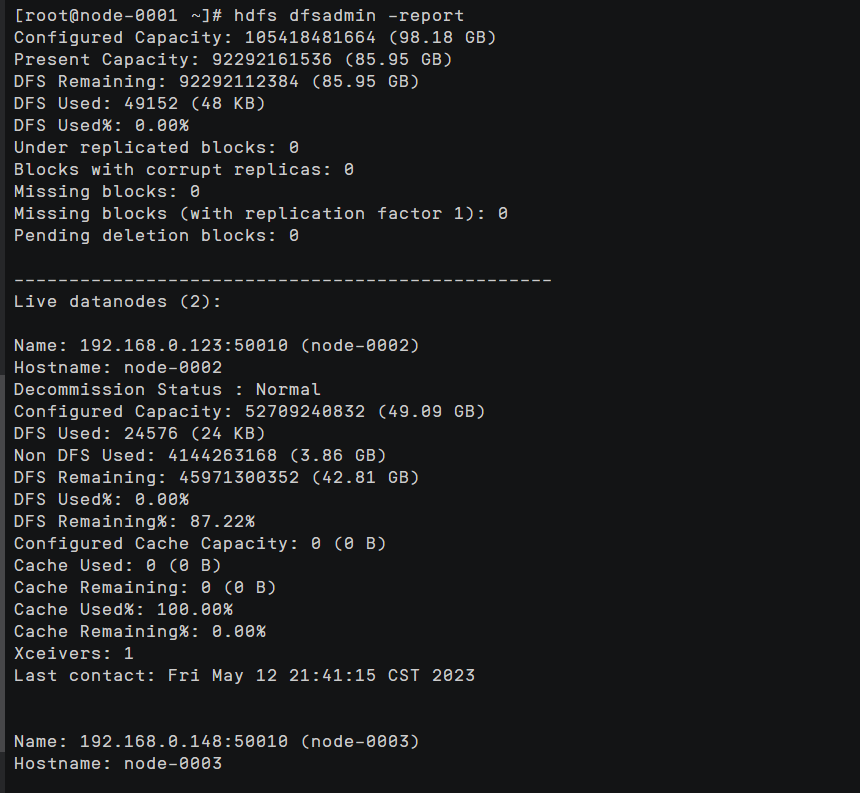
停止HDFS
node-0001节点执行
stop-all.sh测试Hadoop与OBS互联
进入OBS桶,选择“对象”上传文件
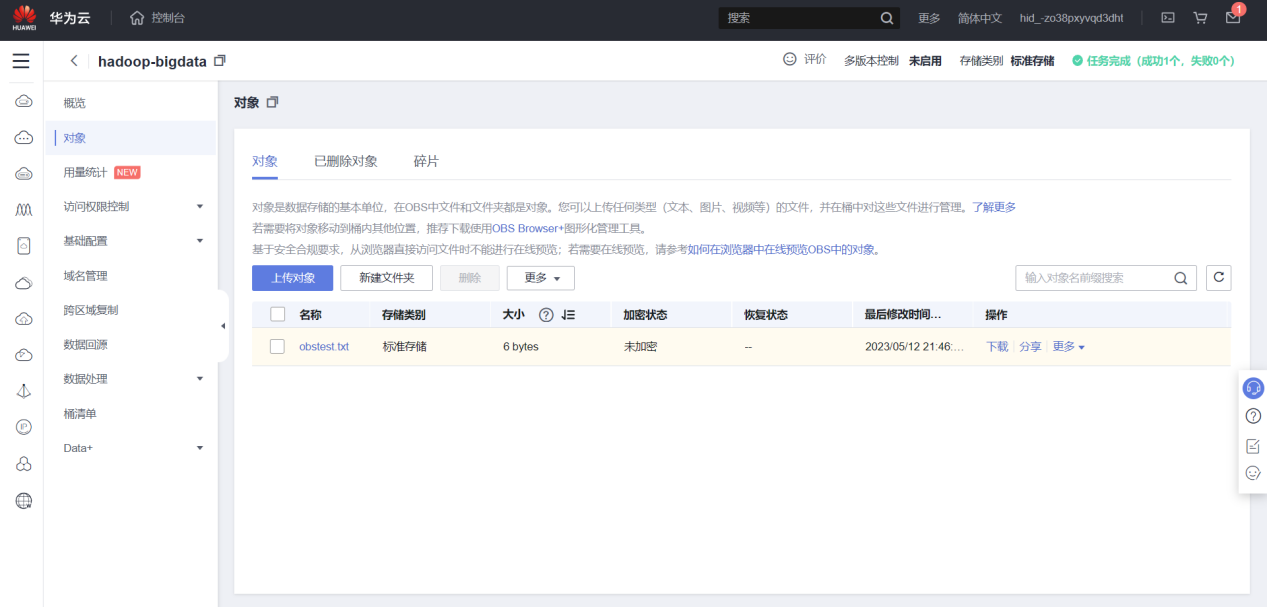
执行hdfs命令查看OBS文件 hadoop-bigdata 是obs的命名
hdfs dfs -ls obs://hadoop-dataserver/
测试能否跑任务
hadoop jar /home/modules/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar pi 100 100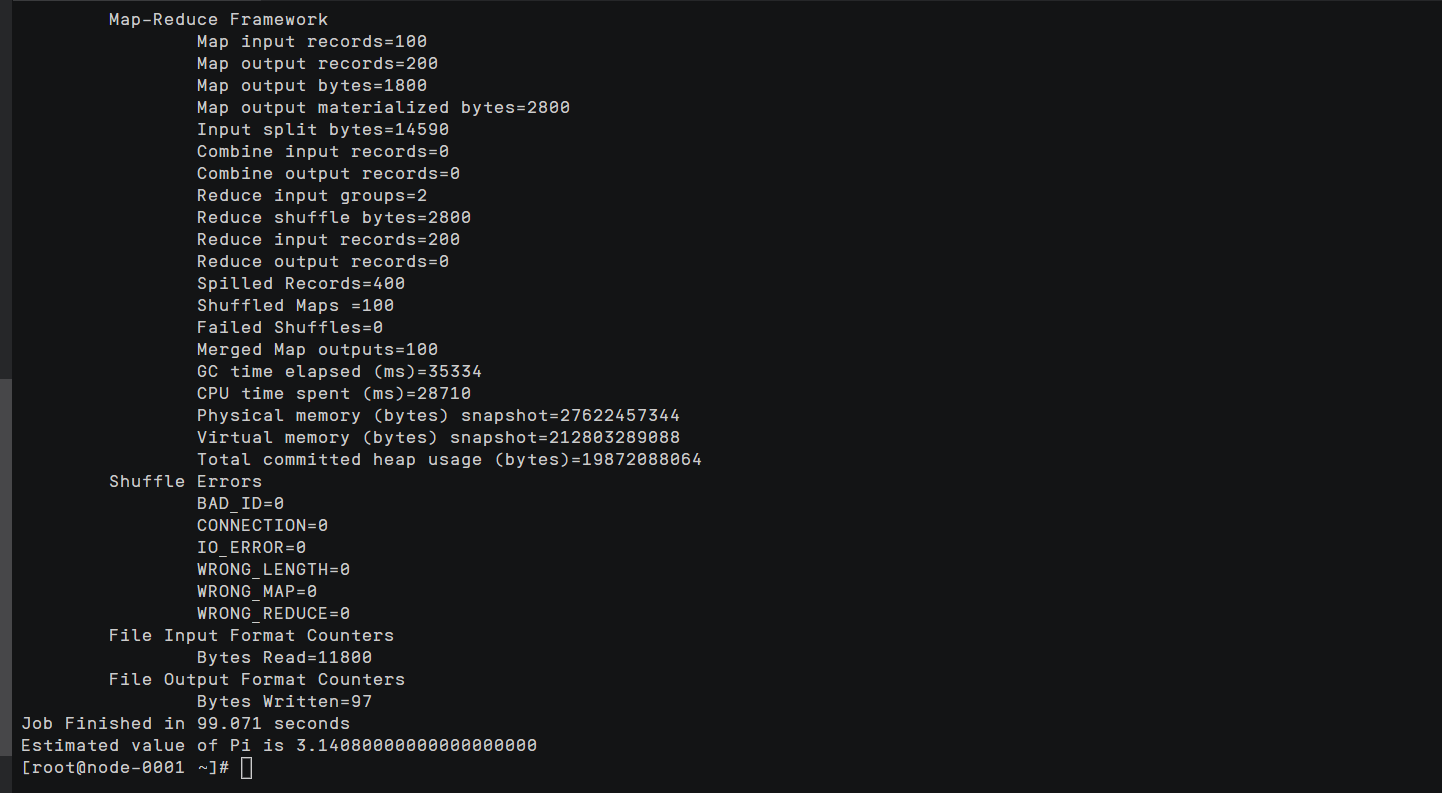
Hadooop集群搭建成功,hadooop成功与OBS互联,并且能跑通任务
搭建Spark集群
安装Spark集群,并使Spark能够读取OBS数据,使Spark集群能够实现存算分离,提高计算性能。
搭建Spark集群
获取spark安装包
node-0001节点下载Spark安装包
cd /root
wget https://bigdata-tools-hw.obs.cn-north-1.myhuaweicloud.com/spark-2.3.0-bin-without-hadoop.tgz解压spark安装包
node-0001节点执行下列命令:
复制安装包到/home/modules目录下
cp /root/spark-2.3.0-bin-without-hadoop.tgz /home/modules
cd /home/modules解压安装包
tar -zxvf spark-2.3.0-bin-without-hadoop.tgz
mv spark-2.3.0-bin-without-hadoop spark-2.3.0配置spark jar包
在node-0001节点,复制jar包到spark/jar下
cp /root/hadoop-huaweicloud-2.8.3-hw-39.jar /home/modules/spark-2.3.0/jars/
cp /home/modules/hadoop-2.8.3/share/hadoop/common/lib/snappy-java-1.0.4.1.jar /home/modules/spark-2.3.0/jars/配置spark配置文件
node-0001节点执行下列命令:
cd /home/modules/spark-2.3.0/conf/
mv spark-env.sh.template spark-env.sh
vim spark-env.sh文件末尾添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_351
export SCALA_HOME=/home/modules/spark-2.3.0/examples/src/main/scala
export HADOOP_HOME=/home/modules/hadoop-2.8.3
export HADOOP_CONF_DIR=/home/modules/hadoop-2.8.3/etc/hadoop
export SPARK_HOME=/home/modules/spark-2.3.0
export SPARK_DIST_CLASSPATH=$(/home/modules/hadoop-2.8.3/bin/hadoop classpath)分发Spark
node-0001节点执行下列命令:
scp -r /home/modules/spark-2.3.0/ root@node-0002:/home/modules/
scp -r /home/modules/spark-2.3.0/ root@node-0003:/home/modules/配置环境变量
各节点执行:
vim /etc/profile添加如下内容:
export SPARK_HOME=/home/modules/spark-2.3.0
export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH各节点执行如下命令,使环境变量生效:
source /etc/profile验证存算分离
查看要计算的文件
本次实验验证Spark与OBS实现存算分离,使用上传的playerinfo.txt文件。
数据如下:
Alex James Lax Genu
Kerry Mary Olivia William
Hale Edith Vera Robert
Mary Olivia James Lax
Edith Vera Robertm Genu计算上述数据的wordcount
启动yarn
start-yarn.sh注:前面如果使用的是start-all.sh,此命令可以省略
启动pyspark
在node-0001节点下执行以下命令
pyspark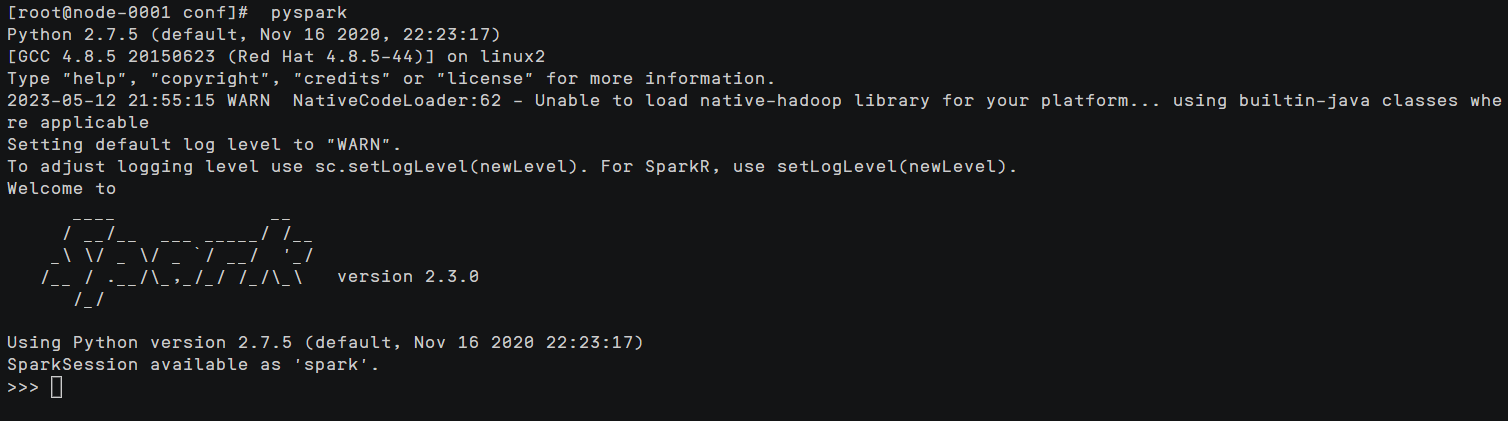
lines = spark.read.text("obs://hadoop-bigdata/playerinfo.txt").rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))或者使用以下命令
$SPARK_HOME/bin/run-example org.apache.spark.examples.JavaWordCount obs://hadoop-dataserver/playerinfo.txt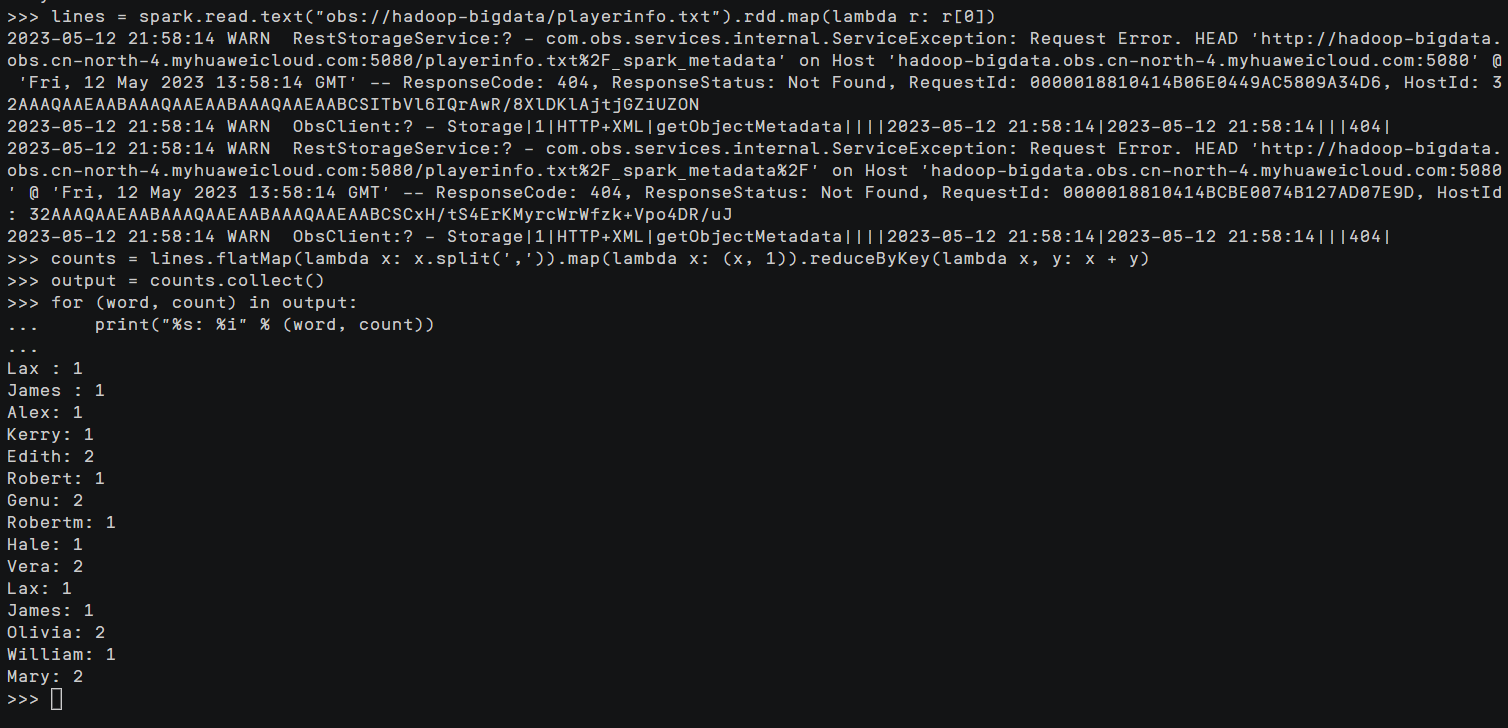
成功安装Spark集群,并使Spark能够读取OBS数据,使Spark集群能够实现存算分离,提高计算性能。

