ElasticSearch是什么
Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
采用以往的模糊查询,模糊查询前置配置,会放弃索引,导致商品查询是全表扫面,在百万级别的数据库中,效率非常低下,而我们使用ES做一个全文索引,我们将经常查询的商品的某些字段,比如说商品名,描述、价格还有id这些字段我们放入我们索引库里,可以提高查询速度。
ES同类产品有哪些
Solr:Solr是用Java编写、运行在Servlet容器的一个独立的全文搜索服务器。
全文检索是什么
全文检索(Full-Text Search):对文本或文档集合进行关键词搜索的技术和功能。它不仅仅是简单的字符串匹配,还包括了分析、索引和搜索等多个步骤。
分词:首先需要对文本进行分析,将其切分成单词或词组的集合。
对分词索引构建:索引是根据关键词和其对应的文档信息构建起来的数据结构,一般采用倒排索引实现。索引会记录每个关键词出现的位置、频率以及相关的文档信息。
当用户输入一个查询词时,全文检索系统会通过查询解析,分析用户输入的关键词,并根据建立的索引进行匹配。全文检索系统会返回与查询词相关性最高的文档列表
倒排索引是什么
以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。
倒排索引(Inverted Index)是一种数据结构,用于实现全文搜索和快速查找的功能。它由两部分组成:词项(Term)和倒排列表(Inverted List)。
- 词项:文档中的某个单词或短语。
- 倒排列表:将每个词项映射到包含该词项的文档列表中。每个文档列表中记录了出现该词项的文档的相关信息,比如文档的标识符、位置等。
倒排索引的优势在于它能够快速定位和匹配文档,而无需遍历所有文档,适用于大规模文本数据的搜索和查询场景。
Lucene是什么
Lucene就是一个jar包,里面包含了各种建立倒排索引的方法,java开发的时候只需要导入这个jar包就可以开发了。
ES 和 Lucene的区别:
Lucene不是分布式的。
ES的底层就是Lucene,ES是分布式的
为什么不用数据库去实现搜索功能
%***%模糊查询
- 需要全表扫描
- 字段里的所有内容都需要匹配
- %*、、、、*%这样的需要全文检索
ES的核心概念
cluster集群,ES是一个分布式的系统
群集是一个或多个节点(服务器)的集合,它们共同保存整个数据,并提供跨所有节点的联合索引和搜索功能。
群集由唯一名称标识,默认情况下为“elasticsearch”。
shard:分片
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
replica:副本
在ES集群中,一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当查询数据的时候,数据是有备份的,它会同时发出命令让有数据的机器去查询结果,最后谁的查询结果快,就要谁的数据
Node节点
就是集群中的一台服务器,存储数据并参与群集索引和搜索功能。
index 索引
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇
索引就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。
type类型
类型是用来定义数据结构的,是索引的逻辑分区
在每一个index下面,可以有一个或者多个type,就像数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
document:文档
文档类似于关系数据库中的一行。
不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。
Field 字段
就像关系型数据库中列的概念,一个document有一个或者多个field组成。
ES写数据过程
- 客户端选择一个 node 发送请求过去,这个 node 就是
coordinating node(协调节点)。 coordinating node对 document 进行路由,将请求转发给对应的 node(有 primary shard)。- 实际的 node 上的
primary shard处理请求,然后将数据同步到replica node。 -
coordinating node如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
写数据底层原理
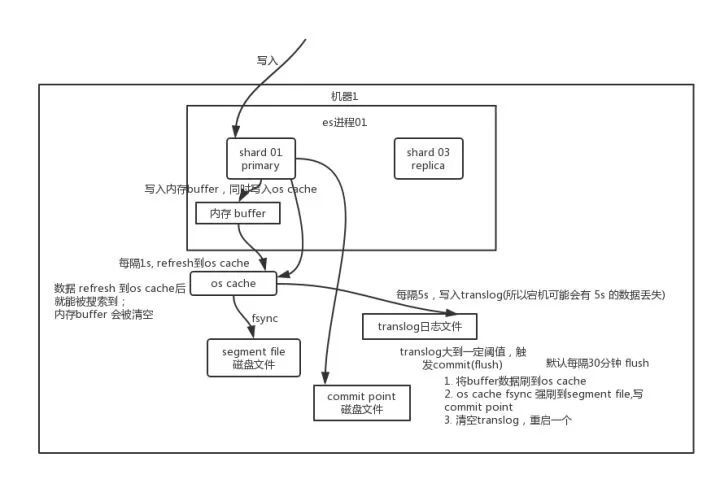
先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据 refresh 到一个新的 segment file 中,但是此时数据不是直接进入 segment file 磁盘文件,而是先进入 os cache 。这个过程就是 refresh。
每隔 1 秒钟,es 将 buffer 中的数据写入一个新的 segment file,每秒钟会产生一个新的磁盘文件 segment file,这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。
但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作,如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
总结:数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
ES搜索数据过程
- 客户端发送请求到一个
coordinate node。 - 协调节点将搜索请求转发到所有的 shard 对应的
primary shard或replica shard,都可以。 - query phase:每个 shard 将自己的搜索结果(其实就是一些
doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - fetch phase:接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
ES读数据过程
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
- 客户端发送请求到任意一个 node,成为
coordinate node。 coordinate node对doc id进行哈希路由,将请求转发到对应的 node,此时会使用round-robin随机轮询算法,在primary shard以及其所有 replica 中随机选择一个,让读请求负载均衡。- 接收请求的 node 返回 document 给
coordinate node。 -
coordinate node返回 document 给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或replica shard 读取,采用的是随机轮询算法。
删除/更新数据底层原理
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。
buffer 每 refresh 一次,就会产生一个 segment file,所以默认情况下是 1 秒钟一个 segment file,这样下来 segment file 会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 segment file 合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘,这里会写一个 commit point,标识所有新的 segment file,然后打开 segment file 供搜索使用,同时删除旧的 segment file。
搭建ES集群需要注意的地方
- 硬件和网络配置:确保硬件配置满足需求,包括足够的内存、存储空间和处理能力。此外,网络配置应该允许节点之间的通信,并具备足够的带宽和低延迟。
- 节点规划和角色分配:根据需求规划集群节点的数量和角色。ES集群通常包括主节点、数据节点和协调节点。主节点负责集群管理,数据节点负责存储和处理数据,协调节点负责请求路由和负载均衡。
- 集群名称和节点标识:为集群指定一个唯一的名称,并为每个节点分配一个独特的标识。这样可以确保集群和节点之间的识别和通信。
- 数据备份和恢复:配置适当的数据备份策略,包括快照和日志备份。这样可以确保在意外情况下能够快速恢复数据。
- 安全设置:保护ES集群的安全性,采取必要的安全措施,如访问控制、身份验证和加密传输。确保只有授权的用户或应用程序可以访问集群。
- 监控和日志:配置监控系统以实时监视集群的状态和性能指标。此外,启用日志记录并配置适当的日志级别,以便在需要时进行故障排除和分析。
- 高可用性和容错性:为了确保ES集群的高可用性,在集群中设置至少3个主节点,并通过复制和分片将数据分布在多个节点上。这样即使某个节点出现故障,集群仍然可以正常运行。
ES查询优化
- 索引设计:根据实际场景和查询需求设计合适的索引,包括字段类型、分词器、分片数、副本数等参数设置。
- 查询语句:查询语句的结构和选项也会影响ES查询性能。避免使用通配符查询、模糊查询或高频率查询,尽可能减少文档匹配和结果排序的负荷。
- 聚合查询:使用合适的聚合函数、分组方式和缓存策略来提高查询性能和响应时间。通过修改聚合查询语句或拆分聚合计算可以进一步优化查询性能。
- 分片和副本:考虑增加分片数、增加副本数、平衡分片负载和优化路由策略。特别是在高并发或大规模数据场景下,需要采取合适的分片和副本配置来确保查询性能和稳定性。
Elasticsearch是如何实现Master选举的
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
如果对某个节点的投票数达到一定的值(n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办
当集群master候选数量不小于3个时,可以通过设置最少投票通过数量,超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题
在并发情况下,Elasticsearch如果保证读写一致
对于写操作
使用乐观并发控制(版本号机制):
- 在更新文档时,每个文档都有一个_version字段,表示当前文档的版本号。
- 客户端在更新期间可以获取文档的版本号,并在提交更新请求时指定该版本号。
- 当版本号与服务器上的当前版本号匹配时,更新请求会被接受;否则,请求将失败。
- 这种方式可以避免数据不一致问题,同时减少了锁的使用。
使用分布式锁:
- 可以引入分布式锁的机制,确保同一时刻只有一个线程可以执行写操作。
- 常见的分布式锁实现方式包括基于ZooKeeper的分布式锁和基于Redis的分布式锁。
- 当一个线程获取到锁后,其他线程需要等待锁释放后才能执行写操作,以保证写操作的一致性。
对于读操作
- 设置replication为sync(默认),使更新操作在主分片和副本分片都完成后才会执行读操作;
- 设置replication为async,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保读到的文档是最新的。
什么是 Analysis(分词)
文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。
在 ES 中,Analysis 是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。
分词器是什么
分词器是专门处理分词的组件,分词器由以下三部分组成:
- Character Filters:针对原始文本处理,比如去除 html 标签
- Tokenizer:按照规则切分为单词,比如按照空格切分
- Token Filters:将切分的单词进行加工,比如大写转小写,删除 stopwords,增加同义语
其中,ES 内置了许多分词器:
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
- Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当做输出
- Pattern Analyzer - 正则表达式,默认 \W+
- Language - 提供了 30 多种常见语言的分词器
- Customer Analyzer - 自定义分词器
说说 Stamdard Analyzer 分词器
它是 ES 默认的分词器,它会对输入的文本按词的方式进行切分,切分好以后会进行转小写处理,默认的 stopwords 是关闭的。
GET _analyze
{
"analyzer": "standard",
"text": "In 2020, Java is the best language in the world."
}运行结果如下:
{
"tokens" : [
{
"token" : "in",
"start_offset" : 0,
"end_offset" : 2,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "2020",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<NUM>",
"position" : 1
},
{
"token" : "java",
"start_offset" : 9,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "is",
"start_offset" : 14,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "the",
"start_offset" : 17,
"end_offset" : 20,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "best",
"start_offset" : 21,
"end_offset" : 25,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "language",
"start_offset" : 26,
"end_offset" : 34,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "in",
"start_offset" : 35,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "the",
"start_offset" : 38,
"end_offset" : 41,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "world",
"start_offset" : 42,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 9
}
]
}可以看出是按照空格、非字母的方式对输入的文本进行了转换,比如对 Java 做了转小写,对一些停用词也没有去掉,比如 in。
其中 token 为分词结果;start_offset 为起始偏移;end_offset 为结束偏移;position 为分词位置。
中文分词器
中文分词有特定的难点,不像英文,单词有自然的空格作为分隔,在中文句子中,不能简单地切分成一个个的字,而是需要分成有含义的词,但是在不同的上下文,是有不同的理解的。
ICU Analyzer 分词器,它提供了 Unicode 的支持,更好的支持亚洲语言
{
"tokens" : [
{
"token" : "各国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "有",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "企业",
"start_offset" : 3,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "相继",
"start_offset" : 5,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "秋招",
"start_offset" : 7,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}可以看到分成了各国,有,企业,相继,秋招,显然比刚才的效果好了很多。
中文分词器还有 IK分词器
说说IK分词器
ik分词器就是一个标准的中文分词器。它可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外,我们还可以定制化分词。
IK分词是一个基于词典的分词器,只有包含在词典的词才能被正确切分,IK解决分词歧义只是根据几条可能是最佳的分词实践规则,并没有用到任何概率模型,也不具有新词发现的功能。
ik分词器2种模式
ik_smart :最粗粒度的拆分
ik_max_word :最细粒度的拆分
自定义字典
2个配置 ext_dict 和 ext_stopwords。分别是扩展和停用字典
在config目录新建 my_ext.dic 和 my_stop.dic
然后配置到 IKAnalyzer.cfg

